Besserer Blocksatz im Web
Silbentrennung
Lange Zeit war die mangelhafte Verfügbarkeit von Silbentrennung im Browser der größte Faktor für schlechten Blocksatz im Web. Das gilt insbesondere für die deutsche Sprache, in der wir in der Regel mit längeren Wörtern zu tun haben.
In den letzten Jahren hat sich hier viel getan: Seit 2011 steht die automatische Silbentrennung mit Hilfe von hyphens: auto zur Verfügung. Dieser CSS-Befehl wird inzwischen von allen großen Browsern unterstützt – die automatische Silbentrennung ist da. Trotzdem bleiben die typografischen Möglichkeiten weit hinter dem, was wir aus Print-Software wie Adobe InDesign gewöhnt sind.
Eine feinere Kontrolle über die Silbentrennung kommt mit dem CSS Text Module Level 4. Richard Rutter hat die neuen Funktionen übersichtlich zusammengefasst. Dazu zählen zum Beispiel das Setzen einer Mindest-Zeichenanzahl vor und nach dem Trennstrich hyphenate-limit-chars und die Limitierung von Trennungen in direkt aufeinanderfolgenden Zeilen hyphenate-limit-lines bzw. die Unterdrückung von Trennungen in der letzten Zeile eines Absatzes hyphenate-limit-last. Für mich besonders interessant: Die Reduzierung von Silbentrennung durch das Definieren einer Trennzone hyphenate-limit-zone. [1]
Ich träume von einer noch weitreichenderen Kontrolle über die Silbentrennung. Es wäre großartig, wenn Content-Produzentïnnen die Trennung bei kritischen Wörtern oder Fachbegriffen mit Softhyphens unterschiedlichen Grades festlegen könnten. »Wenn Du unbedingt trennen musst, dann trenne zunächst hier, meinetwegen auch dort, aber auf keinen Fall an dieser Stelle.«
Blocksatzalgorithmen im Browser
Wie in Teil zwei ausführlich dargelegt, gibt es längst die Technologie für eine vorausschauende, intelligente Berechnung der optimalen Zeilenumbrüche. Trotzdem hat auch im Jahr 2019 kein Browser einen solchen Algorithmus implementiert. Der Line-Breaking-Algorithmus im Browser betrachtet gegenwärtig immer nur eine Zeile. Was nicht reinpasst, wird umbrochen.
Zeitgemäße Alternativen wie der Knuth-Plass-Algorithmus beziehen mehrere Zeilen in ihre Berechnungen der optimalen Umbrüche mit ein. »Wenn ich in Zeile 1 das Wort noch reinquetsche, um Löcher zu vermeiden, was bedeutet das für die Zeilen 2 und 3, und sorgt es am Ende gar für noch viel größere Löcher in Zeile 4?« So entsteht ein ganzer Baum an Möglichkeiten, aus denen der Algorithmus die optimalste Lösung herausfiltert. Genau diese Umbrüche werden dann am Ende auch tatsächlich angewandt.
Bram Stein hat mit seiner Javascript-Implementierung des Knuth-Plass-Algorithmus bewiesen, dass der Einsatz von fortgeschrittenen Blocksatzalgorithmen aus Sicht der Perfomance kein Problem darstellt und eine deutliche Verbesserung im Satzbild bringt. Wir sollten deren Implementierung deshalb unbedingt von den Browserherstellern einfordern!
»Entspannter Blocksatz« (soft justification)
Ein weiterer Ansatz, um digitalen Blocksatz zu verbessern, wäre mehr Menschlichkeit im Algorithmus. Diese These bedarf einer kurzen Erläuterung mit Rückgriff auf Johannes Gutenberg.
In seinen »Untersuchungen zur Geschichte des ersten Buchdrucks« schreibt Paul Schwenke: »Die Einhaltung der gleichen Wortabstände steht in einem gewissen Gegensatz zu einer vollkommenen Gleichheit der Zeilenlängen.«
Gutenbergs Blocksatz gilt nicht etwa wegen einer perfekten rechten Satzkante als beispiellos, sondern vor allem wegen der Gleichmäßigkeit der Wortabstände innerhalb der Zeilen. Schwenke erkennt, »dass [für Gutenberg] eine genau übereinstimmende Zeilenlänge erstrebenswert war, nur dass ihm vielleicht die innere Gleichmässigkeit der Zeilen noch mehr am Herzen lag.« [2]
Und tatsächlich: Wenn man sich den Blocksatz der Gutenberg-Bibel genauer ansieht, stellt man fest, dass die Zeilenlänge nicht immer exakt eingehalten, manchmal sogar deutlich überschritten wurde.

Manchmal ergeben sich beim Schriftsatz Extremfälle, in denen eine geringe Überschreitung der Zeilenlänge das kleinere Übel darstellt. Während früher die Setzer mit ihrer Erfahrung diese Entscheidungen situationsabhängig fällen konnten, ist ein Blocksatzalgorithmus in der Regel auf einen exakten Wert programmiert, den es pixelgenau zu erreichen gilt. Wenn das Zeilenende auch nur um ein Pixel überschritten ist, wird umgebrochen – ohne Rücksicht auf die Wortabstände.
Konkret brauchen wir eine weichere Handhabung der Zeilenlänge, also eine Toleranzzone und ein flexibles Priorisierungssystem für Sollbruchstellen im Text (so etwas wie Softhyphens verschiedenen Grades).
Eine solche Toleranzzone, wie sie im Zusammenhang mit der Silbentrennung im CSS Text Module 4 ja bereits umgesetzt wurde, könnte in Kombination mit dem Knuth-Plass-Algorithmus einen riesigen Unterschied machen. Wenn gleichmäßige Wortabstände und die Vermeidung von Trennungen Priorität hätten und die exakt gleiche Zeilenlänge nicht mehr pixelgenau erreicht werden müsste, hätten wir deutlich besseren und lesbareren Blocksatz im Web.
Wenn wir Gutenberg als Inspiration für besseren digitalen Blocksatz ernst nehmen, muss ein Algorithmus in Ausnahmefällen in der Lage sein – genau wie seinerzeit die Setzer – die vorgegebenen Grenzen der Textspalte zu durchbrechen, um so zu einer neuen Satzform, einer Art »entspannten Blocksatz« (soft justification) zu gelangen.
Besserer Blocksatz durch Variation der Buchstabenbreite
Blocksatz wird besser, je mehr Parameter zum Ausgleich der Zeilenlänge zur Verfügung stehen. Dadurch fällt die Manipulation an jedem einzelnen der Parameter (zum Beispiel am Wortabstand) jeweils weniger stark aus.
Eine Idee für einen zusätzlichen Parameter ist die Variation der Buchstabenbreite. Diese Idee ist nicht neu; in Teil 1 »Gutenbergs Blocksatz« zeige ich, wie Gutenberg bereits mit verschieden breiten Buchstabenvarianten gearbeitet hat.
Anfang der 1990er Jahre setzte sich der Kalligraf und Schriftgestalter Hermann Zapf gemeinsam mit Peter Karow und Margret Albrecht von URW das Ziel, ein Schriftsatzprogramm zu entwickeln, das die Qualität der Gutenberg-Bibel erreicht. Das sogenannte »hz-program« setzte einerseits auf einen Knuth-Plass-Algorithmus, zum anderen bezog es aber auch noch einen weiteren Parameter mit ein: die Buchstabenbreite [3]
Beim sogenannten »glyph scaling« werden nicht die Abstände zwischen den Buchstaben verändert, sondern die Buchstaben an sich um ein bestimmtes Maß zusammengeschoben bzw. auseinandergezogen. Die Technologie hinter dem hz-program wurde später von Adobe gekauft – vermutlich für eine Integration in Adobe InDesign. Es ist nicht bekannt, ob der Code des hz-programs in der aktuellen Version von Adobe InDesign noch Verwendung findet. [4] Anders als im hz-program vorgesehen, verzerrt InDesign nämlich die Buchstaben in die Horizontale, ohne die Strichstärken auszugleichen. Bei Peter Karow und Hermann Zapf behielten die senkrechten Stämme immer die gleiche Breite. Ein »i« konnte also gar nicht verbreitert werden, ein »m« dagegen recht gut. [5]
Glyph scaling ist mit Vorsicht zu genießen und in der Anwendung in Adobe InDesign sicherlich nicht gut umgesetzt. In der Summe mit anderen Parametern kann es aber ein Baustein für einen besseren Blocksatz sein – vorausgesetzt die Strichstärken der Stämme werden beibehalten und das Design der Buchstaben wird nicht durch mechanische Verzerrung entstellt.
Besserer Blocksatz mit Variable Fonts
Im Jahr 2016 wurde der OpenType-Standard um eine entscheidende Funktion ergänzt. Version 1.8 der OpenType-Spezifikation sieht unter anderem sogenannte »OpenType variations« (= variable fonts) vor. In einer Variable-Font-Datei können, im Unterschied zu herkömmlichen OpenType-Fonts, mehrere Schnitte einer Schrift als Master hinterlegt werden. Der Browser kann dann zwischen diesen Master-Schnitten stufenlos interpolieren. Neben vielen weiteren Vorteilen (reduzierte Datenmengen, weniger Requests) können Webdesignerïnnen mit dieser Technologie das Erscheinungsbild der Schrift dynamisch per CSS verändern und sogar animieren.
Für den Blocksatz sind Variable Fonts insofern interessant, als dass sich relativ einfach eine Achse mit schmalen Buchstaben am einen und einer breiteren Version am anderen Ende anlegen lässt. Mit Variable Fonts ist es also möglich, Buchstaben im Browser dynamisch zu verbreitern, ohne dabei ihre Form zu verzerren. Flexible Breite aber mit ausgeglichenen Strichstärken – also genau das, was Herrmann Zapf und URW schon mit dem hz-program machten. Um eine kürzere oder längere Zeile zu erreichen, muss die Schrift nicht gequetscht oder verzerrt werden wie in Adobe InDesign, sondern Typedesignerïnnen legen das Design der unterschiedlich breiten Buchstaben vorher fest und ein Blocksatz-Algorithmus kann dann auf die Breiten-Achse des Variable-Font zurückgreifen. Die inzwischen flächendeckende Verfügbarkeit von Variable Fonts in den Browsern war Ausgangspunkt für den praktischen Teil meiner Masterarbeit: Die Verbesserung von Blocksatz im Web mit schriftgestalterischen Mitteln.
Auf der Robothon-Conference-2018 in Den Haag zeigte Bram Stein anhand seiner Javascript-Implementierung des Knuth-Plass-Algorithmus, wie ein verbesserter Blocksatz mit Hilfe von Variable Fonts umgesetzt werden könnte. Er erweiterte den Algorithmus um den zusätzlichen Parameter »variable Buchstabenbreite« und konnte so die Abweichung der Wortabstände auf ein Minimum reduzieren.
Über diesen rein technischen Ansatz hinaus sind aber auch auch die schriftgestalterischen Möglichkeiten interessant. Von Gutenberg lernen wir, dass mit Abbreviaturen und Ligaturen ein deutlich besseres Satzbild erzeugt werden kann. Wie müsste also ein Font aussehen, der diese historischen Ideen aufgreift und sie mit unseren technischen Errungenschaften kombiniert?
Schriftgestalterische Möglichkeiten
Meine These: Mithilfe eines speziell für diesen Zweck angepassten Variable Fonts und einem veränderten Blocksatz-Algorithmus lässt sich ein noch besseres Satzbild erzeugen.
Als Ausgangspunkt für so einen Font dient eine serifenbetonte Schrift von Prof. Hans R. Heitmann. Die Schrift ist so robust, dass sie eine flexible Veränderung der Buchstabenbreite aushalten kann. [6]
Ausgehend von dem Regular Schnitt der »Arcus Egyptienne« entwickelte ich einen Variable Font. Dabei ist ganz entscheidend, dass die Buchstaben eben nicht gleichmäßig verbreitert oder sogar verzerrt werden. Durch systematische Untersuchung der Gestaltungsspielräume brachte ich in Erfahrung, wo Ansatzpunkte für eine unauffällige Veränderung der Buchstabenbreite sein könnten. Auch wenn jeder Buchstabe individuell betrachtet werden muss, gliederte ich die je 26 Klein- und Großbuchstaben zunächst grob in Gruppen.
Anschließend veränderte ich die Buchstaben individuell, je nach Gestaltungsspielraum, um zu je einem Master mit breiteren bzw. schmäleren Dickten zu gelangen. Essenziell ist dabei die Erhaltung des Grauwertes, damit sich die veränderten Buchstaben optisch gut in das Satzbild integrieren und nicht herausstechen. Bei Veränderung der Binnenräume versuchte ich stets den Grauwert mithilfe der Serifen oder durch Veränderung der Form so auszugleichen, dass sich der Buchstabe im Kontext der Regular-Variante optisch gut einfügt.


Im nächsten Schritt arbeitete ich – wieder inspiriert von Johannes Gutenberg – mit Alternativfiguren, die ich mit Hilfe des Bracket-Tricks auf der wdth-Achse positionierte. Das Interessante an dieser Methode ist, dass die Breakpoints, an denen die Form »umspringt«, für jeden Buchstaben individuell definiert werden können.
Asynchrone Breitenachse
Ein entscheidender Aspekt meiner Lösung ist das Verständnis der wdth-Achse als non-linear bzw. asynchron. Die Idee ist, dass die Buchstaben nicht gleichmäßig schrumpfen und wachsen, wie bei einem Condensed- bzw. Extended-Schnitt einer gewöhnlichen Schrift, sondern sich je nach Gestaltungsspielraum individuell pro Buchstabe verändern oder komplett austauschen können. An einem Ende haben wir also ein standardisiertes System, die wdth-Achse, über die man die Breite der Schrift einstellen kann. Am anderen Ende passieren dann aber unterschiedliche Dinge: Buchstaben werden an bestimmten Stellen verbreitert, Serifen fallen Weg, Formen werden ausgetauscht.
Der Vorteil dieser Architektur: Die Instanz, die den Blocksatz-Algorithmus kontrolliert (also zum Beispiel der Browserhersteller), muss sich keine gestalterischen Gedanken machen, sondern gibt einfach nur die Information »schmaler« oder »breiter« an den Variable Font. Die Gestaltungsentscheidungen werden in den Font und damit in den Verantwortungsbereich der Typedesignerïn ausgelagert, wo auch die nötige Kompetenz liegt.
Experimentelle Ligaturen & Abkürzungen
Eine noch extremere Variabilität, und somit noch besseren Blocksatz, kann man mit der Einbeziehung von Ligaturen erreichen. Ligaturen lassen sich leider nicht als Teil der Breitenachse (wdth-Achse) umsetzen, der Blocksatzalgorithmus könnte sie aber je nach Bedarf zeilenweise an- und ausschalten.
Bei der Umsetzung der Ligaturen für meinen Font orientierte ich mich zunächst an historischen Vorlagen und setzte die üblichen Ligaturen um. Als nächstes richtete ich mein Augenmerk auf häufige Buchstabenpaarungen im Deutschen und Englischen und gestaltete experimentelle Ligaturen für die populärsten Paarungen. Da es sich um eine experimentelle Auseinandersetzung handelt, sind eventuelle Probleme in Bezug auf Lesbarkeit oder Akzeptanz an dieser Stelle bewusst ausgeklammert.
In der Tradition Gutenbergs könnte man schließlich auch noch ein zeitgemäßes Pendant zu dessen Abbreviaturen schaffen. Also: häufig verwendete Wörter abkürzen und durch entsprechende Zeichen ersetzen, zum Beispiel »Euro« → €. Mir ist bewusst, dass hier eine Grenzüberschreitung stattfindet, weil der Text damit inhaltlich verändert wird. Diese Funktion müsste standardmäßig deaktiviert sein und dürfte nur auf ausdrücklichen Wunsch der Anwenderïn zusätzlich zum Einsatz kommen.
Überrascht habe ich festgestellt, dass selbst diese Idee im digitalen Zeitalter bereits aufgegriffen wurde. Der vietnamesische Wissenschaftler Hàn Thế Thành, der unter anderem für die Umsetzung von glyph scaling für pdfTeX verantwortlich ist, hat unter Berufung auf Gutenbergs B42 bereits mit experimentellen Abkürzungen zur Verbesserung von Blocksatz gearbeitet. In seiner Dissertation über eine mikrotypografische Erweiterung des TeX Textsatzsystems finden sich entsprechende Versuche, die Han The Thanh selbst als »heavy experiments« bezeichnet. [7]
Putting it all together
Um verbesserten Blocksatz im Web mithilfe eines speziellen Fonts umzusetzen, ist eine enge Verflechtung von Technik und Gestaltung notwendig: Der Line-Breaking-Algorithmus, der für das Zustandekommen von Blocksatz zuständig ist, und die Features meiner Schrift müssen aufeinander abgestimmt werden. Die Anforderungen an das System lauten:
- Der Line-Breaking-Algorithmus muss um mehrere Parameter (Variable-Font & Ligaturen) erweiterbar sein.
- Priorisierung und Reihenfolge der einzelnen Parameter während des Line-Breaking-Prozesses muss möglich sein.
Leider ist es gegenwärtig nicht möglich, sich in den Blocksatzalgorithmus des Browsers einzuklinken und derartige Erweiterungen selbst vorzunehmen. Der Zeilenumbruch als Teil des Text-Renderingprozesses findet tief in der Layout-Engine statt. Meines Wissens ist hier kein Eingriff möglich. Deshalb habe ich zum Testen meiner Verbesserungen einen einfachen Line-Breaking-Algorithmus (ohne Knuth und Plass Entscheidungsalgorithmus) in Javascript nachgebaut.
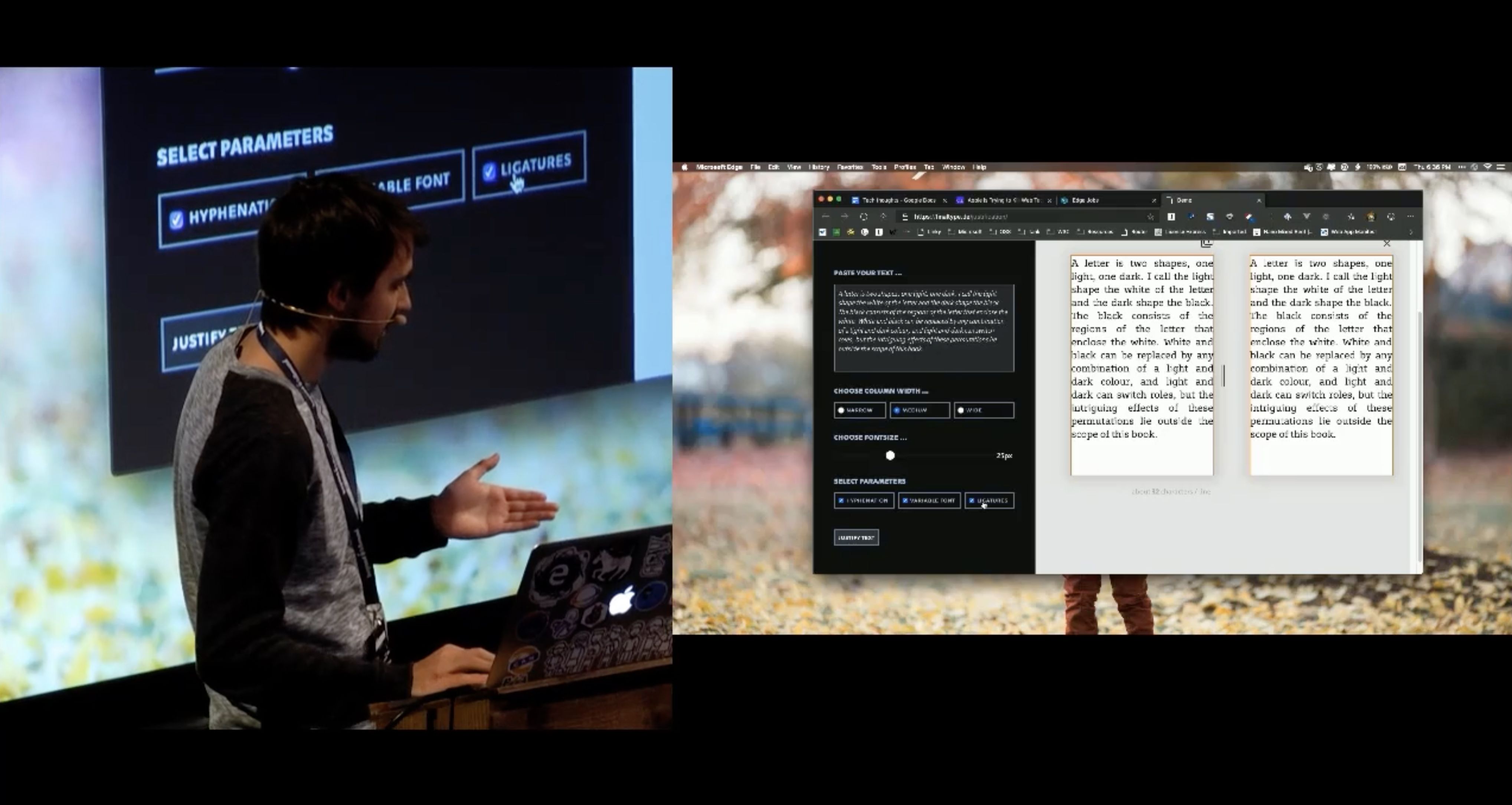
Dieser Blocksatz-Simulator funktioniert im Prinzip genau wie der Algorithmus im Browser – mit dem entscheidenen Unterschied, dass ich an jeder Stelle eingreifen und jeden Parameter einzeln ansteuern kann.
Es kann eine beliebiger Text eingegeben werden, der dann in einen Blocksatz verwandelt wird. Die einzelnen Parameter Silbentrennung [8], Variable-Font und experimentelle Ligaturen können über Buttons einzeln ein- und ausgeschaltet werden. Die konkrete Verbesserung des Blocksatzes durch schriftgestalterische Methoden wird mit diesem Tool anschaulich und greifbar. → Live-Demo öffnen
Bessere Typogafie einfordern
Bisher bleibt digitaler Schriftsatz, insbesondere im Web, weit hinter seinen technischen Möglichkeiten. Die Umsetzung des Knuth-Plass-Algorithmus für das Web ist längst überfällig.
Darüber hinaus könnten wir Typedesignerïnnen durch einen kreativen Umgang mit der wdth-Achse von Variable Fonts unseren Beitrag leisten, Blocksatz im Web weiter zu verbessern. Für solche Verbesserungen brauchen wir allerdings Schnittstellen in und mehr Kontrolle über die bestehenden Line-Breaking-Algorithmen in den Browsern. Das volle Potenzial lässt sich nur durch eine enge Verknüpfung von Gestaltung (Typedesign) und Programmierung (Blocksatzalgorithmus im Browser) ausschöpfen.
Fortschritte im Bereich der Webtypografie sind grundsätzlich möglich (wie bei der Silbentrennung) – auch wenn der Weg bis zu einer flächendeckenden Lösung in der Regel sehr lang ist. Eine realistischen Betrachtung unserer Handlungsspielräume zeigt: Nur wenn wir weiterhin unsere Forderungen an das W3C und die Browserhersteller adressieren und uns nicht mit den aktuellen Möglichkeiten zufriedengeben, haben wir eine Chance auf bessere Typografie im Web.
Die Einbindung des Knuth-Plass-Entscheidungsalgorithmus wäre ein erster naheliegender Schritt, um Blocksatz im Web ein gutes Stück voranzubringen. Dazu Bram Stein:
»I think the best way forward is to get the line breaking algorithm standardised as an opt-in CSS feature. That way, browsers interested in implementing Knuth/Plass could do so and web developers can enable it. Once we see some real-world usage it might motivate other browsers to implement it as well.«
In diesem Artikel skizziere ich außerdem die Idee eines »entspannten Blocksatzes« (soft justification), also die Möglichkeit für den Algorithmus, in Ausnahmefällen aus dem gewohnten Raster auszubrechen und die Parameter anders zu priorisieren. Um echten Fortschritt für Typografie im Web zu ermöglichen, braucht es beides: Die Kreativität von Gestalterinnen und Gestaltern, bestehende Techniken auszureizen, und gleichzeitig auf Seiten des W3C und der Browserhersteller den Mut zur Veränderung und den Willen, die Technik voranzutreiben.
Dieser Text basiert teilweise auf der Masterarbeit von Johannes Ammon mit dem Titel »Blocksatz im Web – Verbesserungen durch Algorithmen und Variable Fonts«. Johannes absolvierte 2019 den Studiengang Gutenberg Intermedia | Type + Code an der Hochschule Mainz.
- Der Algorithmus versucht in der Regel immer die optimale Zeilenlänge zu erreichen, wodurch bei aktiver Silbentrennung relativ viele Trennungen am Zeilenende entstehen. Durch die Definition einer Toleranzzone mit hyphenate-limit-zone lässt sich ein Maximum an Weißraum definieren, der am Ende einer Zeile noch akzeptabel ist. So kann der Algorithmus öfter ganze Wörter umbrechen und auf eine Trennung verzichten.
- vgl. Schwenke, Paul: Untersuchungen zur Geschichte des ersten Buchdrucks, Königliche Bibliothek zu Berlin, 1900, S.41
- vgl. Zapf, Hermann: About micro-typography an the hz-program, in: Electronic Publishing V6(3), 1993, S. 286
- Wikipedia: Hz-program, https://en.wikipedia.org/wiki/Hz-program, 19.12.2018, 17:30 Uhr
- vgl. Eng, Torbjørn: InDesign, the hz-program and Gutenberg’s secret, <http:// www.typografi.org/justering/gut_hz/gutenberg_hz_english.html>, 19.12.2018, 17:30 Uhr
- Nicht jede Schrift bringt diese Voraussetzungen mit. Betrachtet man beispielsweise die römische Capitalis, so spielen die klassischen Proportionen der Großbuchstaben eine entscheidende Rolle und sollten nicht verändert werden. Erst seit dem 17. Jahrhundert werden Versalien mit annähernd gleicher Breite gestaltet.
- vgl. Hàn Thế Thành: Microtypographic extensions to the TEX typesetting system. Masaryk University Brno, 2000
- Für die Simulation der Silbentrennung greife ich auf Hyper.js https://github.com/bramstein/hypher von Bram Stein zurück.